SQL Server 数据库执行计划和索引访问原理
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
执行计划是数据库系统为了执行SQL查询而生成的一种指导性的路线图,它描述了数据库引擎如何获取数据、操作数据以及返回结果。执行计划中的统计信息是指数据库系统收集和存储的关于表、索引、列等对象的数据分布、数据量、数据分布情况以及数据变化情况等信息。这些统计信息对于数据库优化和查询性能的评估都至关重要。 原本打算分开两篇说明执行计划与索引访问原理。当前就简单说明一下,不会深入执行计划原理。建议先了解下索引的存储原理SQL Server 数据库索引原理 还是实践说明更容易了解。
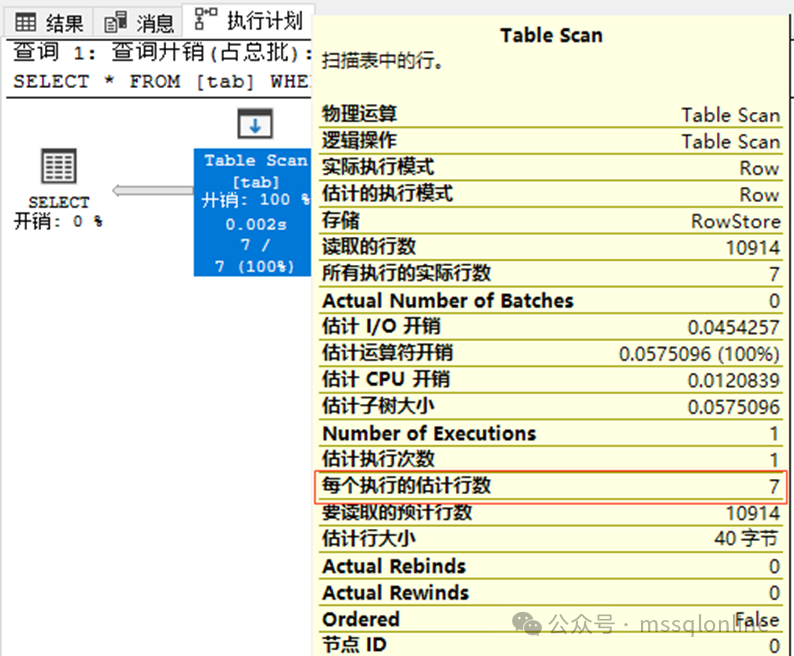
以上我创建了一张表,并执行查询检查执行计划情况。 接下来就看看统计信息,sp_helpstats 可参考表有哪些统计信息,SHOW_STATISTICS 可以查看某个统计信息的分布情况。
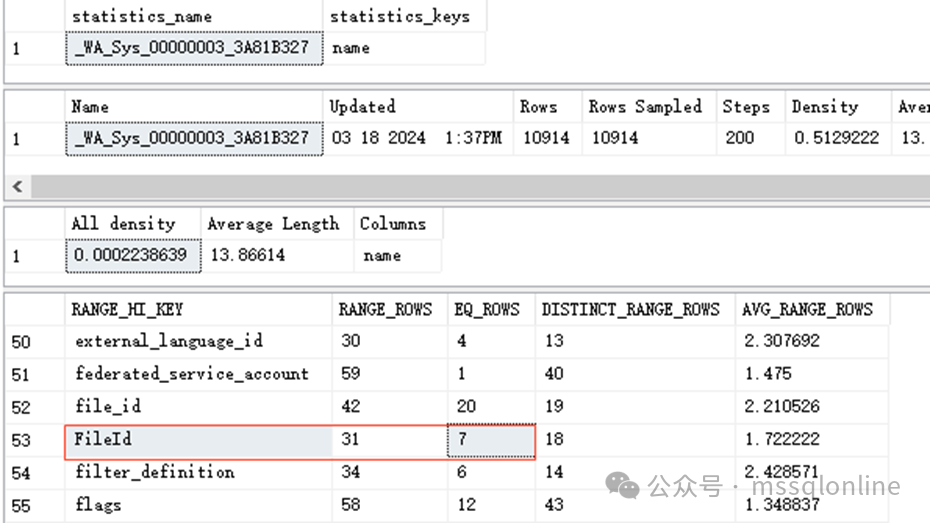
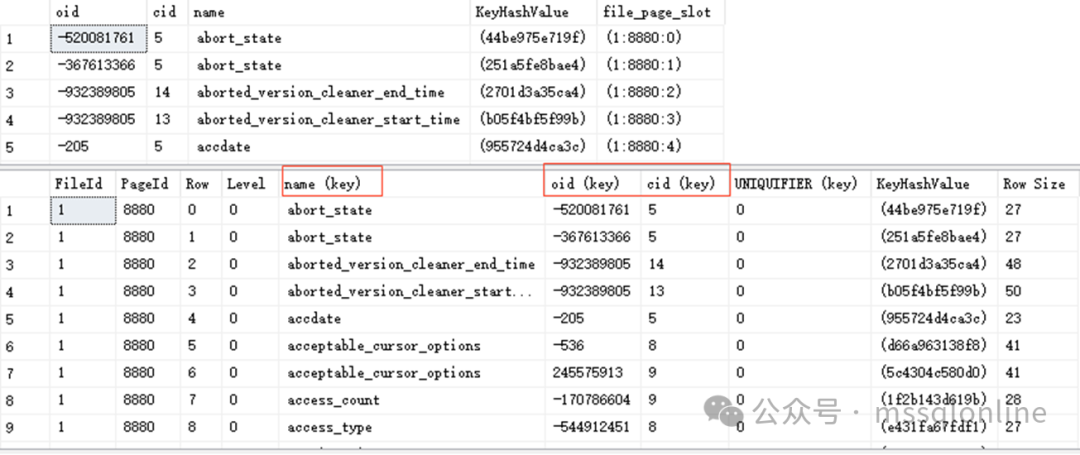
在统计信息里面,数据将字段name的值按顺序分成200份,每一份包含多个不同的值,每个值可能有多行。以上图统计信息为例,字段name的值为“FileId”的数据有7行,字段name值在范围大于“file_id”、小于“FileID”的数据有31行,去重之后有18行。 因此,当系统在估计查询计划的时候,会根据条件中不同的比较符号,估计出不同的行数。如果统计信息不准确,那么生成的执行计划可能就不是最优的,会导致使用更大的代价。系统会触发统计信息的更新,但对于一些大表、变化量大的表来说,触发更新的阈值也随之较大,这就要求我们需要定期地更新统计信息。 在 SQL Server 2016 (13.x) 前
自 SQL Server 2016 (13.x) 起
保持统计数据最新非常重要,以确保实际行和估计行尽可能紧密地对齐。对于每次插入、更新和删除更改数据,分布都会发生变化,并且可能会扭曲估计。这些偏差可能会导致查询计划不够理想并导致性能下降。设置每周更新统计作业可以帮助他们保持最新状态。 现在我们创建一个非聚集索引,创建索引后,相关的索引统计信息也会自动生成,与字段name的统计信息没多大差别。
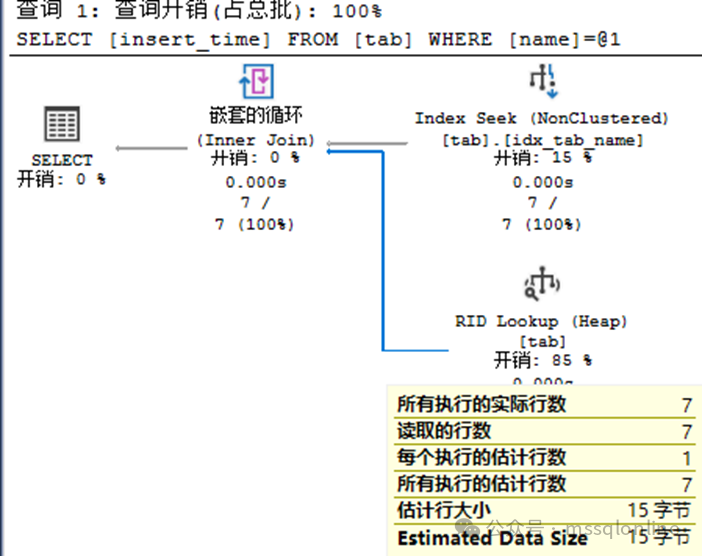
可以看到,查询使用了该非聚集索引idx_tab_name的索引查找,但是为什么还有嵌套循环、进行 RID Lookup 呢?因为查询是获取所有的字段,但是索引只有字段name、以及执行堆表的 RID,通过RID进行了一次回表查询,将其他字段值全部取出。要了解索引原理,参考文章 XXXXX。 在执行计划的图中,你可以点击相应的箭头,返回的数据量越大,箭头也会越粗。从上图可以分析,通过字段name查找出7行数据,每行数据都回表查询一次,累计回表7次。要了解IO读取情况,参考文章 XXXXX。 现在创建一个聚集索引,看看执行计划是什么样的。
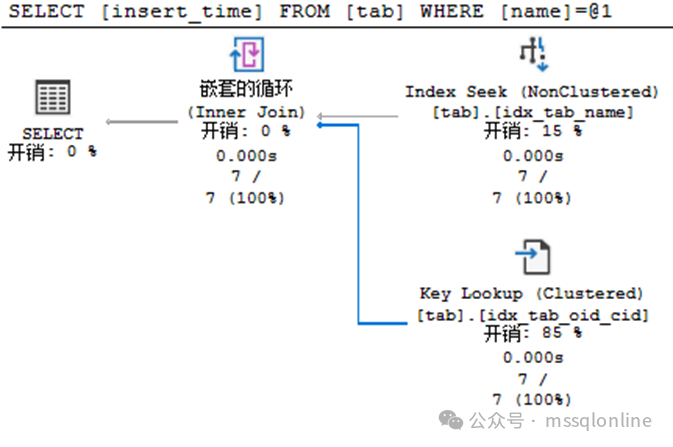
执行计划与“RID Lookup”差别不大。创建聚集索引后,堆表转为聚集索引表。那么非聚集索引中叶节点存储的不在是RID,而是聚集索引的键列(oid,cid)。在执行计划中,回表查找则显示为“Key Lookup”。同样可以看到,“Key Lookup”的开销占比85%,在数据量较大的时候,影响会更加明显。 那么,应该如何优化这类查询呢?可以创建以下一种索引,复合索引或者包含列索引。
复合索引相信大家比较好理解,在索引B+Tree结构中,中间的索引节点会存在2个字段的值。而在包含列的索引中,字段insert_time只存在于叶子节点。也就是在这2个索引中,insert_time的值都包含在内。当查询insert_time时,不需要再回表查询了。这种优势可以用在分页查询中。 如果我执行以下这个SQL,执行计划是怎样的呢?
可以看到只查找了非聚集索引idx_tab_name,这是因为该非聚集索引已经包含了聚集索引键列,不用再回表了。如其中的一个叶节点如下。
在 SQLServer 中,成本开销主要参考CPU开销与IO开销,而IO开销的计算主要是参考页面的读写情况。现在我们重新来过,验证IO的读取计算。
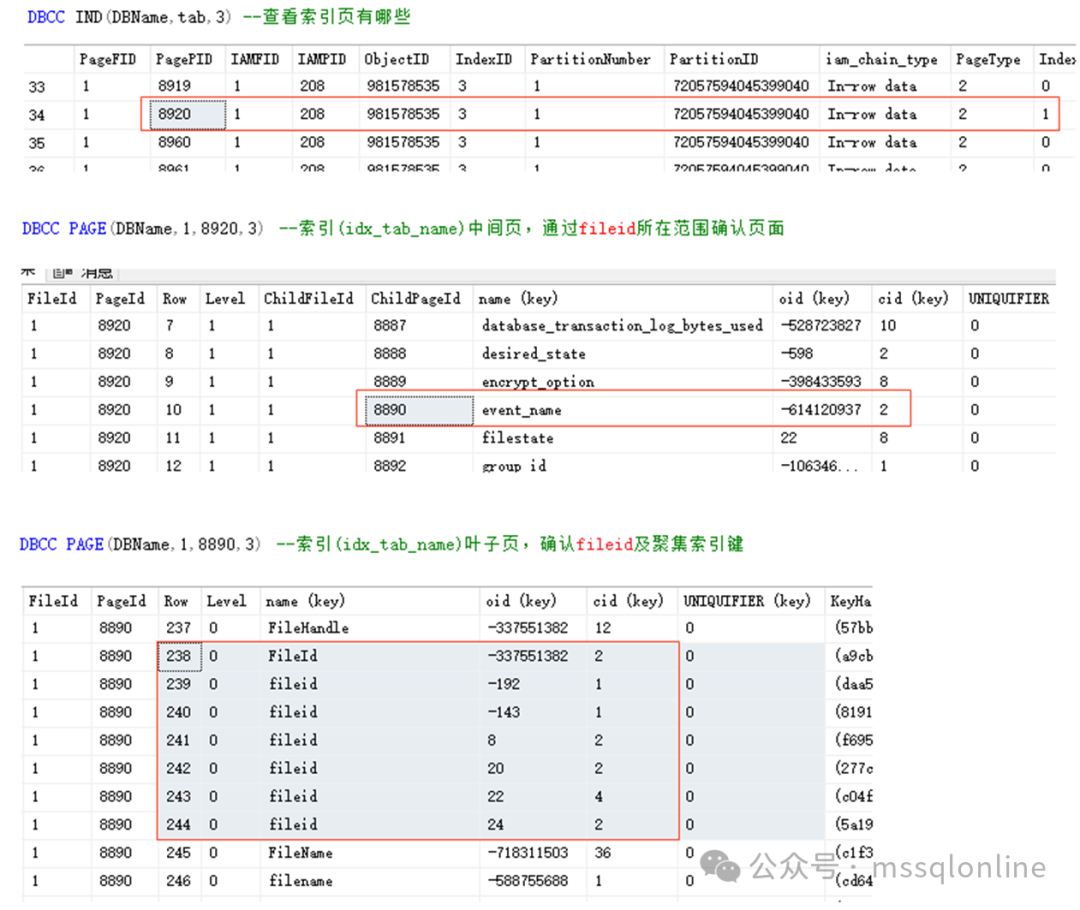
(7 行受影响) 表“tab”。扫描计数 1,逻辑读取次数 16,物理读取次数 0,页面服务器读取次数 0,预读读取次数 0,页面服务器预读读取次数 0,LOb 逻辑读取次数 0,LOB 逻辑读取次数 0,LOB 页面服务器读取次数 0,LOB 预读读取次数 0,LOB 页面服务器预读读取次数 0。 不管扫描聚集索引还是非聚集索引,扫描次数只有一次,不要考虑同一张表非聚集索引的嵌套循环。逻辑读取次数为16,说明读取了16个页面,页面已经缓存中。这16个页面我们也可以猜到引擎是如何读取的。即先通过非聚集索引读取其子叶页面,再回表通过聚集索引读取其子叶。 非聚集索引idx_tab_name需要访问3个页面,1个IAM页、1个索引页、1个叶子页面。
非聚集索引的叶子页可以确认fileid的数据行数为7行,因为我们查询的是字段insert_time,在非聚集索引不存在,需要回表查询。回表就需要确认聚集索引键列(oid,cid)。我以第一行为例,继续查看相关页面。
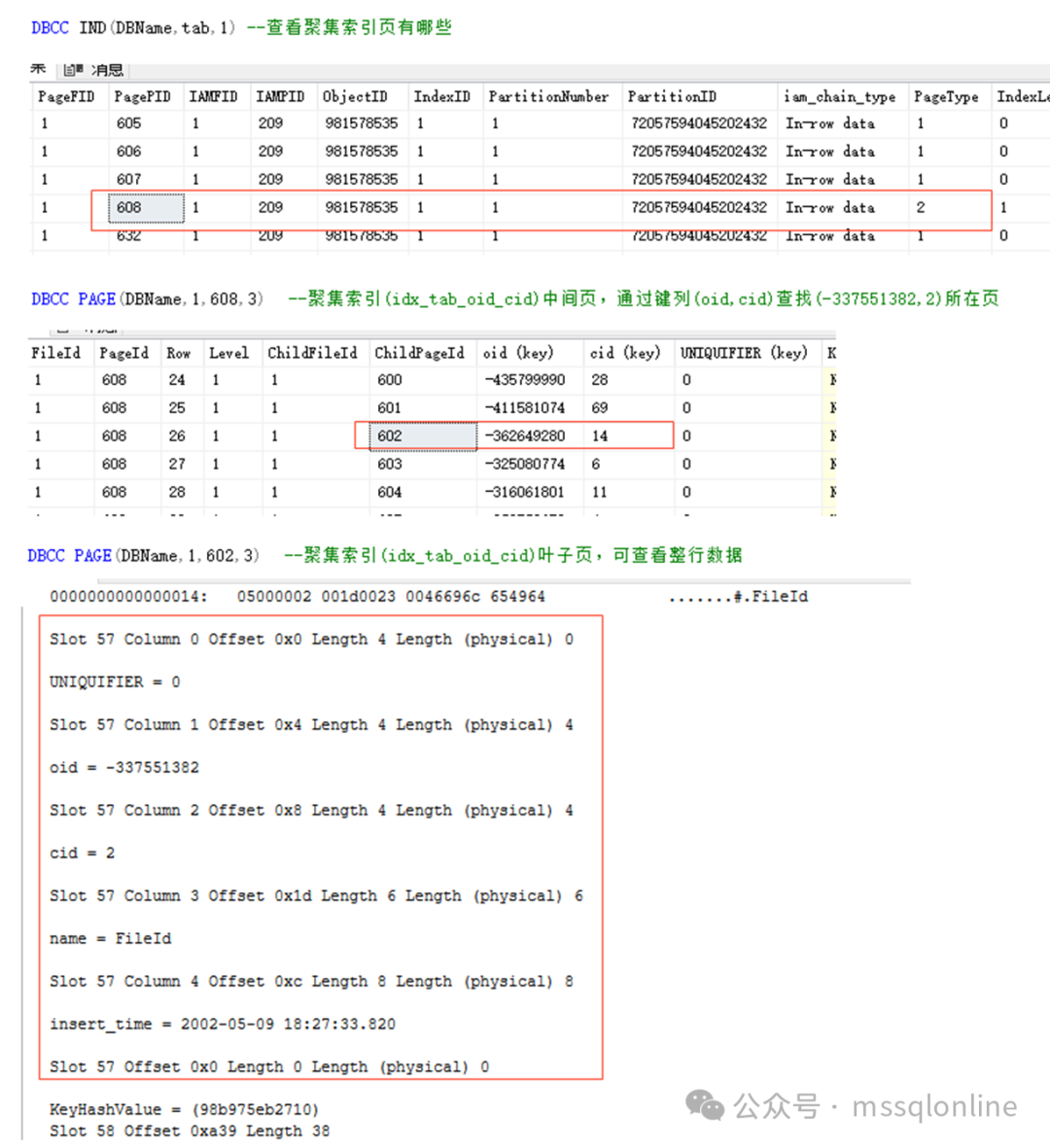
在聚集索引中,通过键列(oid,cid)查找(-337551382,2)所在叶子页,需要读取聚集索引中间索引节点1个页面,1个叶子页面,也就是2个页面。
总页面数为1 + 1 + 1*7*(1 + 1) = 16 ,即我们最开始 看到的一样。 为了SQL有效地使用索引,我们应尽量获取必要的字段,不要使用星号。当我们有较多表关联的时候,条件和关联字段应建立相关索引,尽量减少回表二次查询。回表查询开销是比较大的,尤其字段较多的时候。数据是按行存储的,当我们取某字段的时候,整行数据也会读取到内存中,而行数据是存储在页面中的,这也将导致更多的IO读取。 阅读原文:原文链接 该文章在 2025/1/10 11:05:16 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886