sql查询IN里面有重复的值,怎么不去重查询,这是一条思路
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
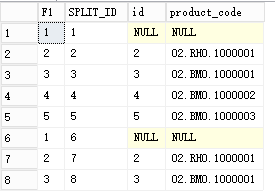
 :sql查询IN里面有重复的值,怎么不去重查询,这是一条思路 :sql查询IN里面有重复的值,怎么不去重查询,这是一条思路 场景:多数情况,我们用IN查询,里面有重复值,sql会自动过滤IN里面的重复值,造成查询的结果是小于IN里面的条数,但是某些特殊情况,我们是需要匹配所有的项目都要有信息存在。 例如:id in (1,2,3,4,5,1,2,3),其中1,2,3是重复的。如果直接用 in,只会返回1,2,3,4,5的数据,不能完整的体现1,2,3,4,5,1,2,3所有数据状况。
如何一对一体现1,2,3,4,5,1,2,3的数据状况,思路大概是:建立一个中间件(数据库表)。将in的数据割裂成一个临时表,再去关联查询每一行的数据是否存在。
该文章在 2024/11/20 18:31:32 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886



 建立中间表 。
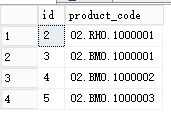
建立中间表 。 left join,左关联视图,当右边有信息则ID存在,否则不存在
left join,左关联视图,当右边有信息则ID存在,否则不存在